Erfurt, Berlin, Heilbronn & Zürich
SEO & SEA seit 2008
15-köpfiges Team
Bei der Google Search Console (kurz: GSC), die ehemals auch als Google Webmaster Tools bezeichnet wurde, handelt es sich um ein kostenfreies Google-Tool zur Analyse und Optimierung von Websites. Die GSC kommt vor allem im Rahmen der Suchmaschinenoptimierung zum Einsatz und gibt Webmastern zahlreiche Empfehlungen zur Optimierung einer Website. Darüber hinaus erhalten Nutzer Warnungen bei Problemen, welche beispielsweise die Indexierung, Backlinks oder mobile Nutzerfreundlichkeit betreffen. In diesem Beitrag erhalten Sie einen genauen Überblick über verschiedene Fehlermeldungen im Abdeckungsbericht der GSC und deren Bedeutung. Darüber hinaus zeigen wir Ihnen mögliche Lösungswege auf. Auf Fehlermeldungen in den Bereichen “Nutzerfreundlichkeit”, “Verbesserungen” etc. wird an dieser Stelle nicht genauer eingegangen.
Im Index Abdeckungsbericht der Google Search Console (im GSC-Menü links unter “Seiten”) werden alle indexierten und nicht-indexierten URLs gelistet:
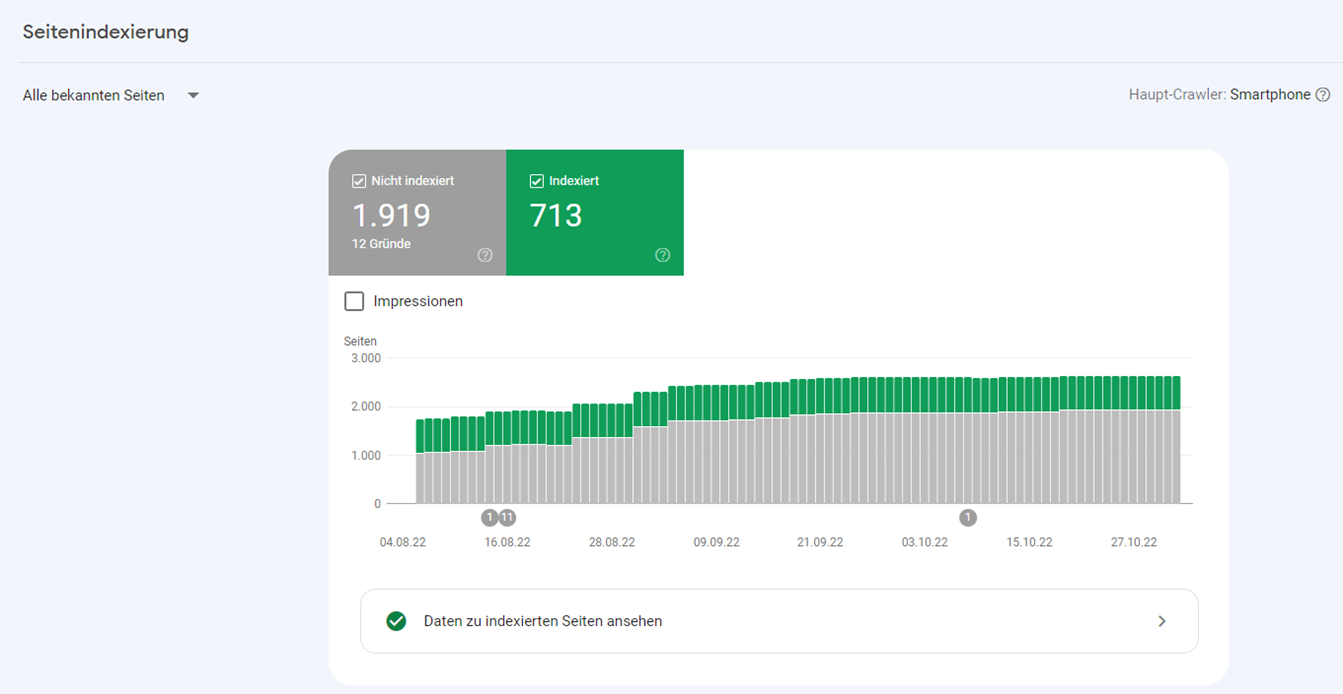
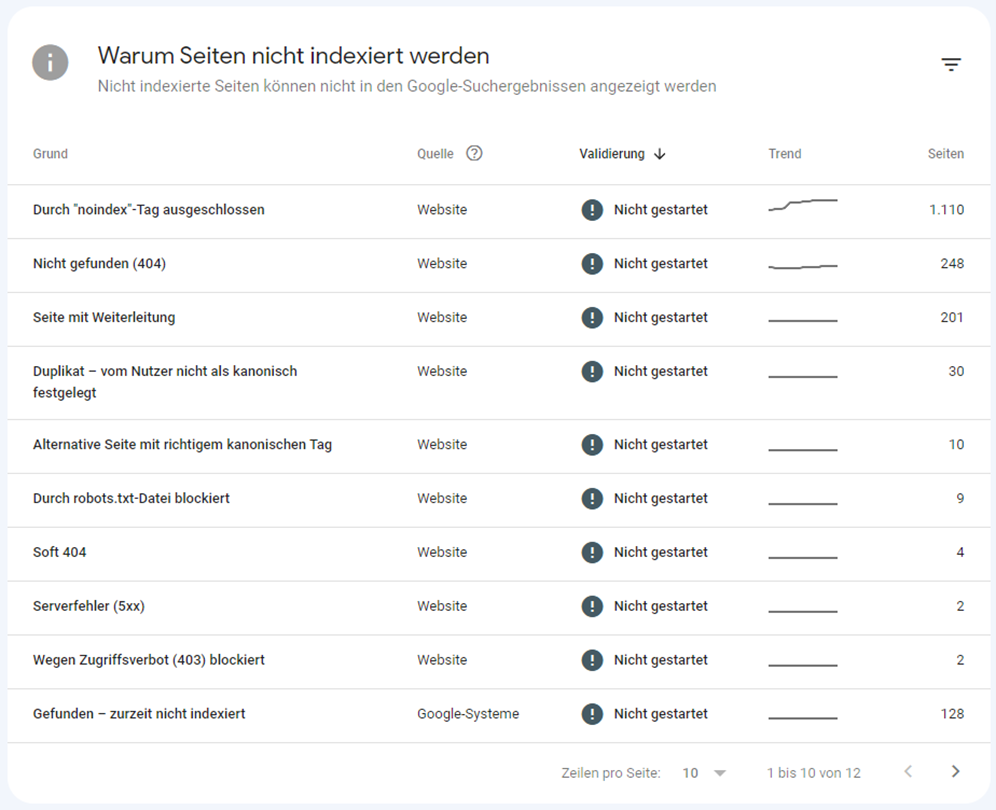
Indexiert bedeutet, dass die Seiten grundsätzlich in der Google-Suche ausgegeben werden. Nicht-indexierte URLs sind demnach aus den Google Suchergebnissen ausgeschlossen. Gründe für die Nicht-Indexierung werden wie hier als Fehlermeldungen angegeben:
Über die Unterscheidung in “Indexiert” und “Nicht Indexiert” hinaus, lassen sich die URLs auch nach mit der Sitemap eingereichten (“Alle eingereichten Seiten”) und nicht eingereichten (“Nur nicht eingereichte Seiten”) Seiten filtern:
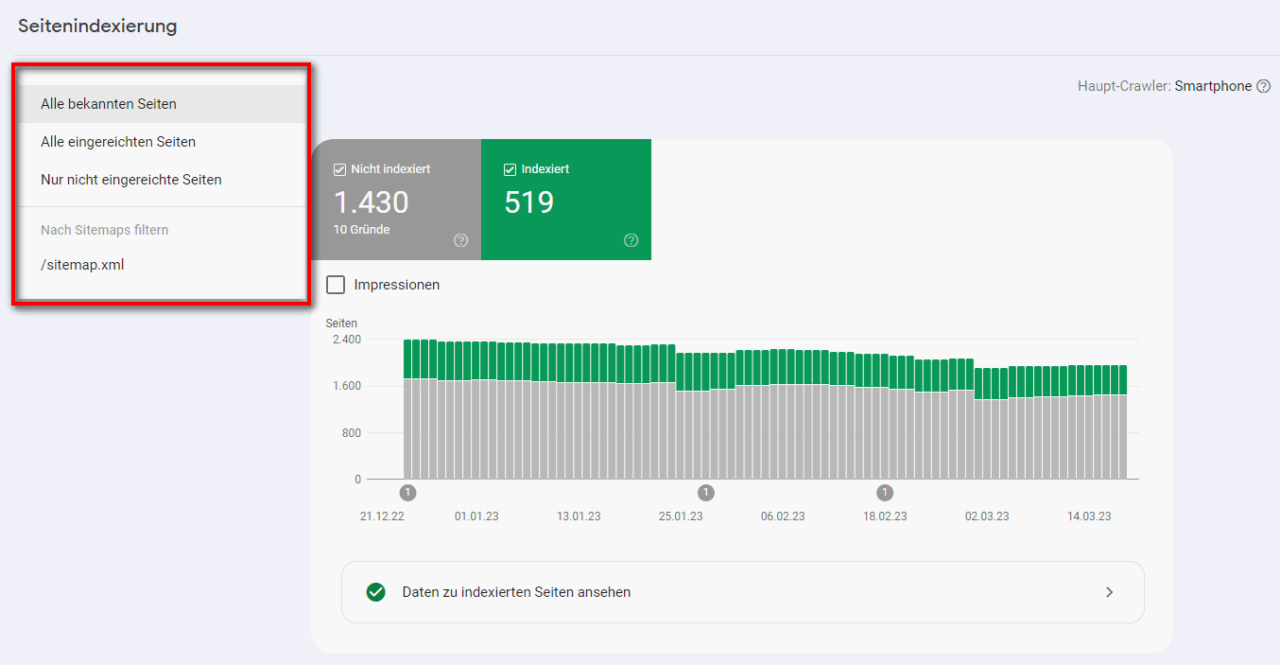
Diese Informationen geben zum einen Auskunft darüber, wie gut oder schlecht gepflegt eine Sitemap ist. Zum anderen lassen sich wichtige Handlungsempfehlungen für die Optimierung der Sitemap ableiten. Bei der Sitemap handelt es sich um eine maschinenlesbare URL-Liste (in der Regel XML-Datei) für Suchmaschinen. Sie dient Websitebetreibern dazu, Indexierung und Crawling einer Website zu steuern. Mit der Sitemap signalisiert man Google, welche URLs einer Website besonders wichtig sind und entsprechend indexiert werden sollen.
Ob eine Fehlermeldung im Abdeckungsbericht der Google Search Console tatsächlich problematisch ist, lässt sich nicht pauschal beantworten. Grundsätzlich lohnt es sich hier aber, immer erst einmal einen kühlen Kopf zu bewahren und nicht in Panik zu verfallen. Viele Fehlermeldungen sind verhältnismäßig harmlos. Dennoch sollten Sie den Abdeckungsbericht regelmäßig checken und entsprechende Missstände vor allem auf lange Sicht beheben.
Die aufgeführten Fehlermeldungen geben Hinweise auf Optimierungspotenziale hinsichtlich der Qualität einer Website. Umso höher diese ist, desto einfacher lassen sich Struktur und Inhalte von Crawlern (Software-Programme, die das Internet durchsuchen) erfassen. Dies wirkt sich wiederum positiv auf die Sichtbarkeit in Suchmaschinen aus. Ein weiterer Vorteil ist die Übersichtlichkeit. So lassen sich gerade schwerwiegende Probleme (beispielsweise die Nicht-Indexierung wichtiger Seiten) deutlich schneller erkennen und beheben. Die Search Console Daten von Webseiten mit geringer Qualität sind voll von unterschiedlichen Fehlermeldungen. Gerade unerfahrene GSC-Nutzer übersehen in der Folge häufig größere Probleme mit Handlungsbedarf und stürzen sich stattdessen auf unerhebliche Fehlermeldungen, die sich kaum oder gar nicht auf die Google-Rankings auswirken.
Damit Sie genau wissen, was es mit den verschiedenen Fehlerbezeichnungen im Abdeckungsbericht auf sich hat, stellen wir Ihnen nachfolgend alle wichtigen Fehlermeldungen der Google Search Console vor. Dabei gehen wir neben der Bedeutung auch gleich auf mögliche Problemlösungen ein, damit Sie genau wissen, wie Sie Fehler zu bewerten und mit selbigen umzugehen haben. Hier zunächst eine allgemeine Übersicht über die Fehlermeldungen, deren Bedeutung und Lösungsansätze:
| Fehlermeldung | Bedeutung | Lösung |
|---|---|---|
| Serverfehler (5xx) | Server gibt bei Anfrage 5xx-Fehler zurück (Seite ist nicht aufrufbar) | Die betroffene Seite aufrufen a.) erreichbar – kein Handlungsbedarf b.) nicht erreichbar – Serverfehler beheben |
| Seite mit Weiterleitung | URLs, die auf andere Seite weitergeleitet werden | Weiterleitungen sind a.) richtig gesetzt – kein Handlungsbedarf b.) falsch gesetzt – Weiterleitung entsprechend ändern |
| Umleitungsfehler | URLs, die nicht oder nicht richtig weitergeleitet werden |
|
| Durch robots.txt-Datei blockiert / Warnung: Indexiert, obwohl durch robots.txt-Datei blockiert | URLs werden indexiert / nicht indexiert, obwohl / da sie in der robots.txt-Datei gelistet sind | Betroffene URLs a.) sollen indexiert werden – URL aus robots.txt-Datei entfernen b.) sollen nicht indexiert werden – auf “noindex” setzen |
| Durch “noindex”-Tag ausgeschlossen | URLs werden von Google ignoriert (weder gecrawlt noch indexiert) | Betroffene URLs a.) sollen indexiert werden – “noindex”-Tag entfernen b.) sollen nicht indexiert werden – kein Handlungsbedarf |
| Alternative Seite mit richtigem kanonischen Tag | URLs sind Duplikate von Seiten, die Google als kanonisch einstuft | Betroffene Seite a.) verweist korrekt auf kanonische URL – kein Handlungsbedarf b.) verweist auf falsche kanonische URL – kanonischen Tag auf die gewünschte URL setzen |
| Gefunden / Gecrawlt – zurzeit nicht indexiert | URLs werden von Google gefunden / gecrawlt, aber nicht indexiert | Indexierung händisch anstoßen. Wenn das nicht hilft:
|
| Wegen nicht autorisierter Anforderung (401) blockiert | URLs werden durch eine Autorisierungsanforderung für den Googlebot blockiert | Seite soll:
a.) nicht gecrawlt / indexiert werden – URL aus Sitemap entfernen und ggf. auf “noindex” setzen b.) gecrawlt / indexiert werden – Erforderliche Anmeldung entfernen |
| Wegen Zugriffsverbot (403) blockiert | URLs werden bewusst durch eine Zugriffssperre gesperrt | Zugriffsverbot ist a.) gewünscht – URL durch “noindex”-Tag oder robots.txt-Datei blockieren b.) nicht gewünscht – nicht angemeldete Nutzer zulassen / Googlebot auf Zulassungsliste setzen |
| Gesendete URL nicht gefunden (404) | URLs geben beim Abruf 404-Fehlermeldung zurück |
|
| Soft 404-Fehler | Server sendet beim Aufruf einen 200- oder 302-Statuscode, obwohl die Seite nicht mehr vorhanden ist und eigentlich eine 404-Fehlermeldung die richtige Antwort wäre | URL prüfen:
|
| Eingereichte URL wegen eines anderen 4xx-Problems blockiert | Server gibt eine 4xx–Fehlermeldung zurück, die zu keiner der vorangegangenen 4xx-Probleme passt | URL individuell prüfen – Lösung hängt vom Ergebnis des URL-Checks ab |
| Duplikat – vom Nutzer nicht als kanonisch festgelegt | URL ist ein Duplikat einer anderen Seite, es wurde keine der URLs als kanonisch gekennzeichnet – Google wählt die kanonische (originale) Seite eigenständig aus | URL prüfen, um herauszufinden, welche Seite als kanonisch bestimmt wurde: a.) Richtige URL als kanonisch bestimmt – Kein Handlungsbedarf b.) Falsche URL als kanonisch bestimmt – Richtige kanonische Seite angeben |
| Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt | URL wurde für mehrere Seiten als kanonische Seite gekennzeichnet, nach Einschätzung von Google eignet sich jedoch eine andere Seite besser als kanonische Seite | URL prüfen, um herauszufinden, welche Seite als kanonisch bestimmt wurde: a.) Richtige URL als kanonisch bestimmt – Kein Handlungsbedarf b.) Falsche URL als kanonisch bestimmt – Inhalte anpassen oder von Google bestimmte URL aus dem Index entfernen |
Im weiteren Verlauf dieses Beitrags werden die verschiedenen Fehlermeldungen, ihre Bedeutung und mögliche Lösungsansätze im Detail betrachtet.
Tipp!
Die aufgeführten Fehlermeldungen richtig zu interpretieren und geeignete Maßnahmen abzuleiten, ist trotz der umfangreichen Aufarbeitung im Rahmen dieses Beitrags nicht ganz einfach, vor allem für Laien. Wir von seonicals® helfen Ihnen mit unserem Know-how aus über 15 Jahren Erfahrung im Bereich SEO gerne dabei, die Probleme Ihrer Website zu identifizieren sowie entsprechende Optimierungsmaßnahmen abzuleiten und zu priorisieren.
Zu dieser Fehlermeldung heißt es von Google: “Ihr Server hat bei Anforderung der Seite einen 5xx-Fehler zurückgegeben”. Das bedeutet, dass der Googlebot entweder nicht auf die Seite zugreifen konnte, die Anfrage abgelaufen ist oder die Website ausgelastet war und die Anfrage deshalb abgebrochen wurde. Die Lösung: Versuchen Sie, die betroffenen Seiten einmal aufzurufen. Häufig treten Serverfehler nur vorübergehend auf. Die in der Google Search Console aufgeführten Seiten lassen sich bei Überprüfung daher oft problemlos aufrufen. Ist dies der Fall, besteht kein weiterer Handlungsbedarf. Lassen sich die betroffenen Seiten über längere Zeit nicht aufrufen, sollte die Ursache des zugrundeliegenden Serverfehlers gefunden und behoben werden.
Hier werden alle URLs aufgelistet, die intern oder extern verlinkt sind, allerdings nicht mehr existieren und entsprechend weitergeleitet werden. In den meisten Fällen besteht hier kein Handlungsbedarf. Überprüfen Sie einmal, ob die Weiterleitungen richtig gesetzt sind. Ist dies der Fall, müssen Sie keine weiteren Schritte unternehmen. Sind falsche Weiterleitungen gesetzt, sollten Sie die Weiterleitungen entsprechend ändern.
Unter “Umleitungsfehler” aufgeführte URLs existieren nicht mehr (404) und werden nicht richtig oder überhaupt nicht weitergeleitet. Überprüfen Sie die htaccess-Datei und die Umleitungsregeln oder richten Sie (falls nicht erfolgt) eine Weiterleitung auf eine passende Seite ein.
Bei der robots.txt-Datei handelt es sich um eine Textdatei, die Crawlern wie dem Googlebot signalisiert, welche Seiten gelesen werden dürfen und welche nicht. Sie wird von Crawlern entsprechend als erstes ausgelesen. Damit die robots.txt-Datei auch tatsächlich gefunden wird, muss sich die Datei im Hauptverzeichnis der Domain befinden. Es gibt pro Domain immer nur eine robots.txt-Datei.
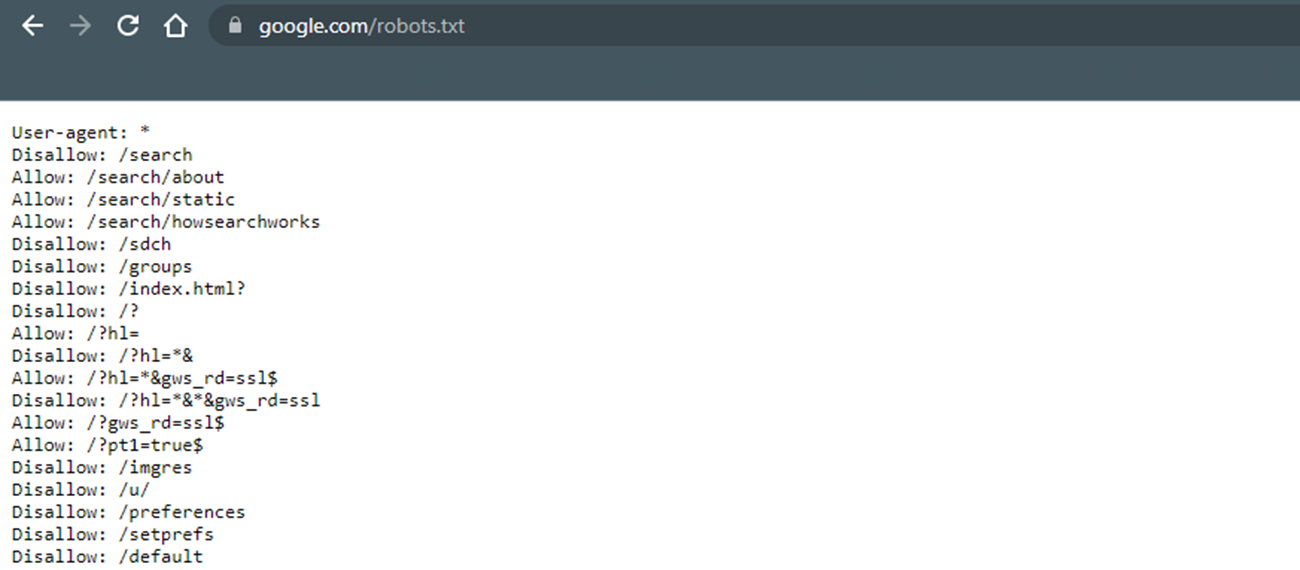
Die Fehlermeldung “Durch robots.txt-Datei blockiert” bedeutet, dass die entsprechenden URLs nicht indexiert werden, da sie sich in der robots-txt-Datei befinden. Eine Indexierung solcher durch robots.txt blockierten Seiten ist unter Umständen aber dennoch möglich, sofern Google weitere Informationen (beispielsweise durch interne Verlinkungen) finden kann, ohne die Seite zu crawlen. Ist dies der Fall und sollen die betroffenen URLs tatsächlich nicht in der Google-Suche ausgegeben werden, sollten sie anstelle des robots.txt lieber mit dem “noindex”-Tag versehen werden. Ist die Indexierung der betroffenen URLs dagegen gewünscht, sollten Sie sie aus der robots.txt-Datei entfernen.
Die Warnung “Indexiert, obwohl durch robots.txt-Datei blockiert”, betrifft genau den im vorherigen Abschnitt beschriebenen Fall, dass eine URL von Google indexiert wird, obwohl sie in der robots.txt-Datei gelistet ist. In diesem Fall müssen Sie für die betroffenen URLs prüfen, ob:
Die gelisteten Seiten wurden mit dem “noindex”-Tag versehen (“Indexierung zulässig? – Nein: “noindex” im Meta-Tag “robots” erkannt”) und werden von Google entsprechend ignoriert und folglich nicht indexiert. Wenn Sie nicht möchten, dass die betroffenen URLs indexiert werden, ist alles in Ordnung. Möchten Sie dagegen, dass ein oder mehrere der aufgeführten URLs indexiert werden, sollten Sie den “noindex”-Tag entfernen.
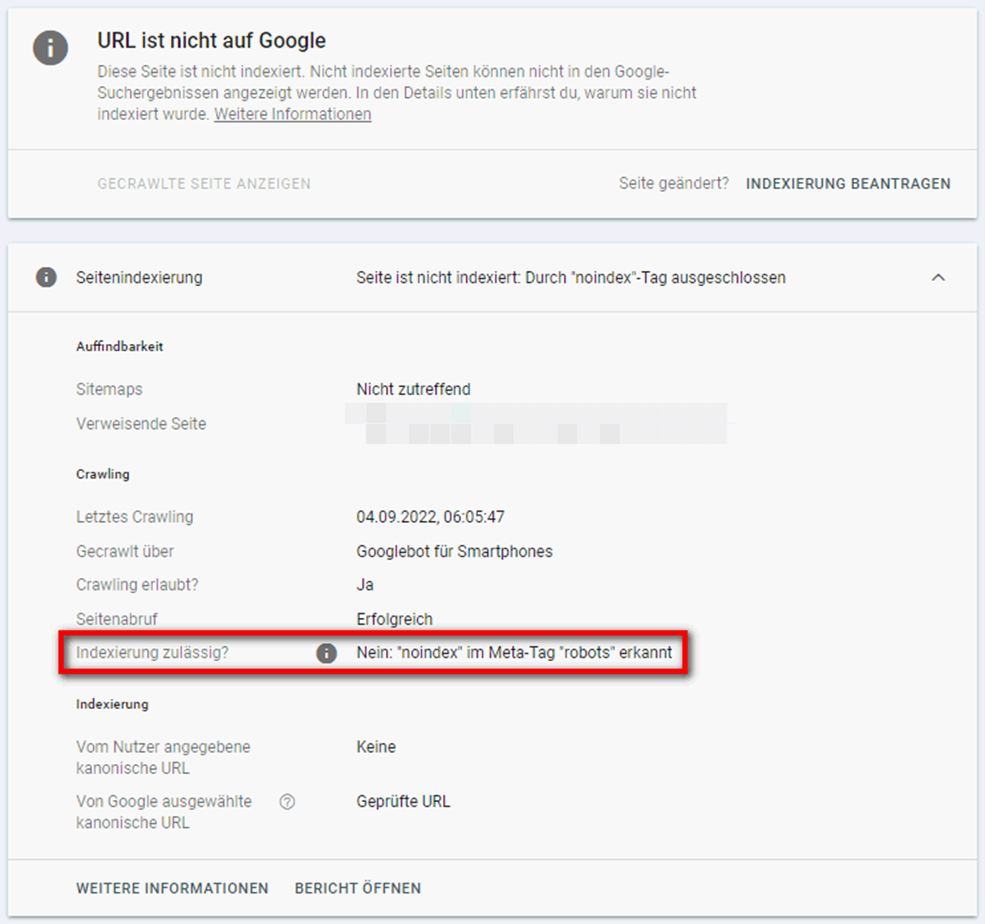
Die Fehlermeldung “Alternative Seite mit richtigem kanonischen Tag” hat viel mit den Themen “Duplikate” und “Canonical Tags” zu tun. Von Duplikaten spricht man im Rahmen der Suchmaschinenoptimierung, wenn zwei oder mehr Seiten mit einem identischen oder sehr ähnlichen Inhalt existieren. Mit Hilfe von Canonical Tags kann man Google signalisieren, welches der Duplikate indexiert werden soll. Dabei handelt es sich für Google jedoch immer nur um einen Hinweis, nicht um eine Regel! Ist kein kanonischer Tag hinterlegt, wählt Google selbst eine Seite als Original aus. Teilweise werden von Google auch andere Seiten als kanonisch bestimmt.
Zurück zur eigentlichen Fehlermeldung: Die aufgeführten URLs sind Duplikate von Seiten, die Google als kanonisch einstuft. Verweist die Seite wie im nachfolgenden Beispiel korrekt auf die kanonische Seite, besteht kein Handlungsbedarf:
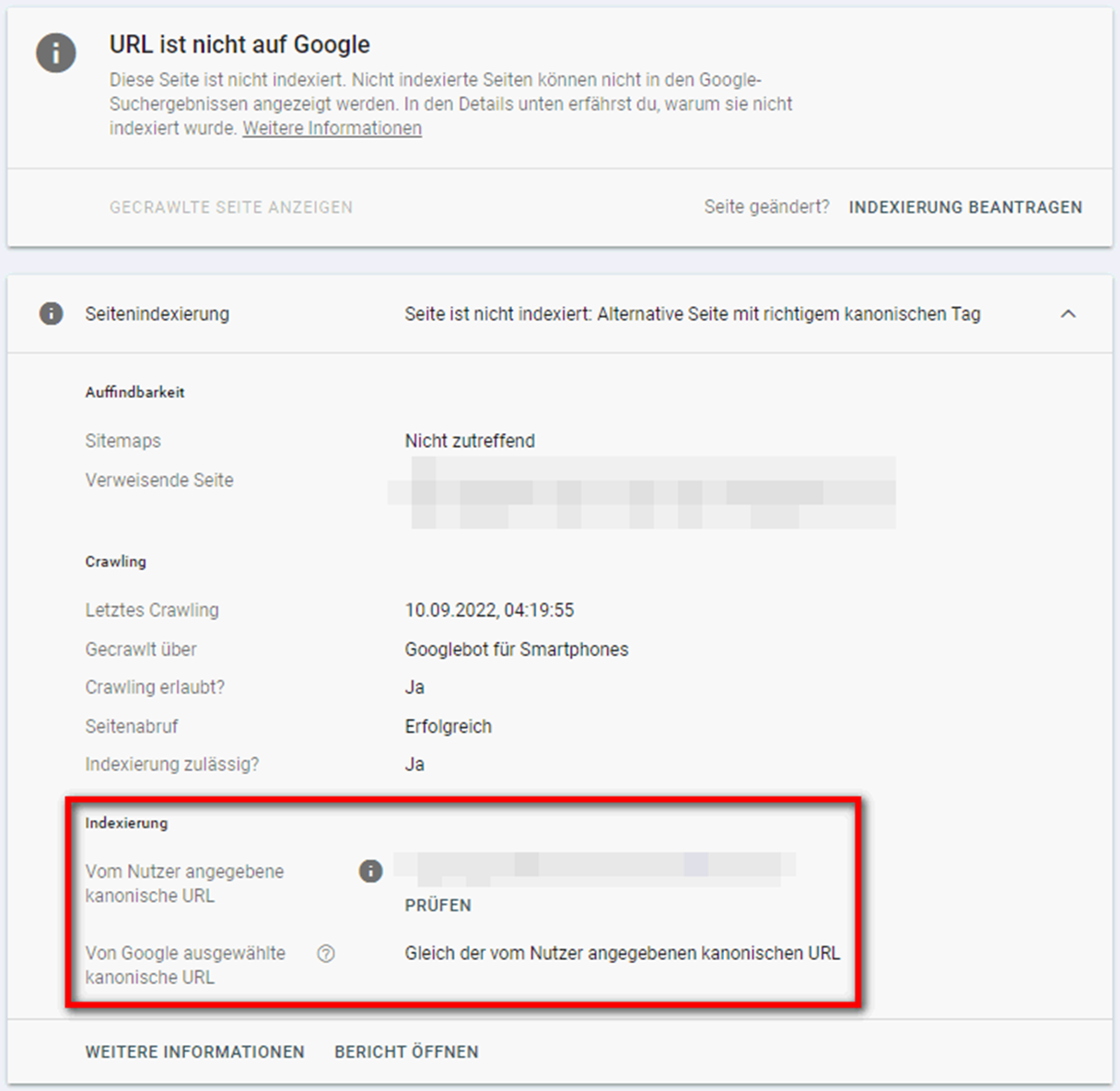
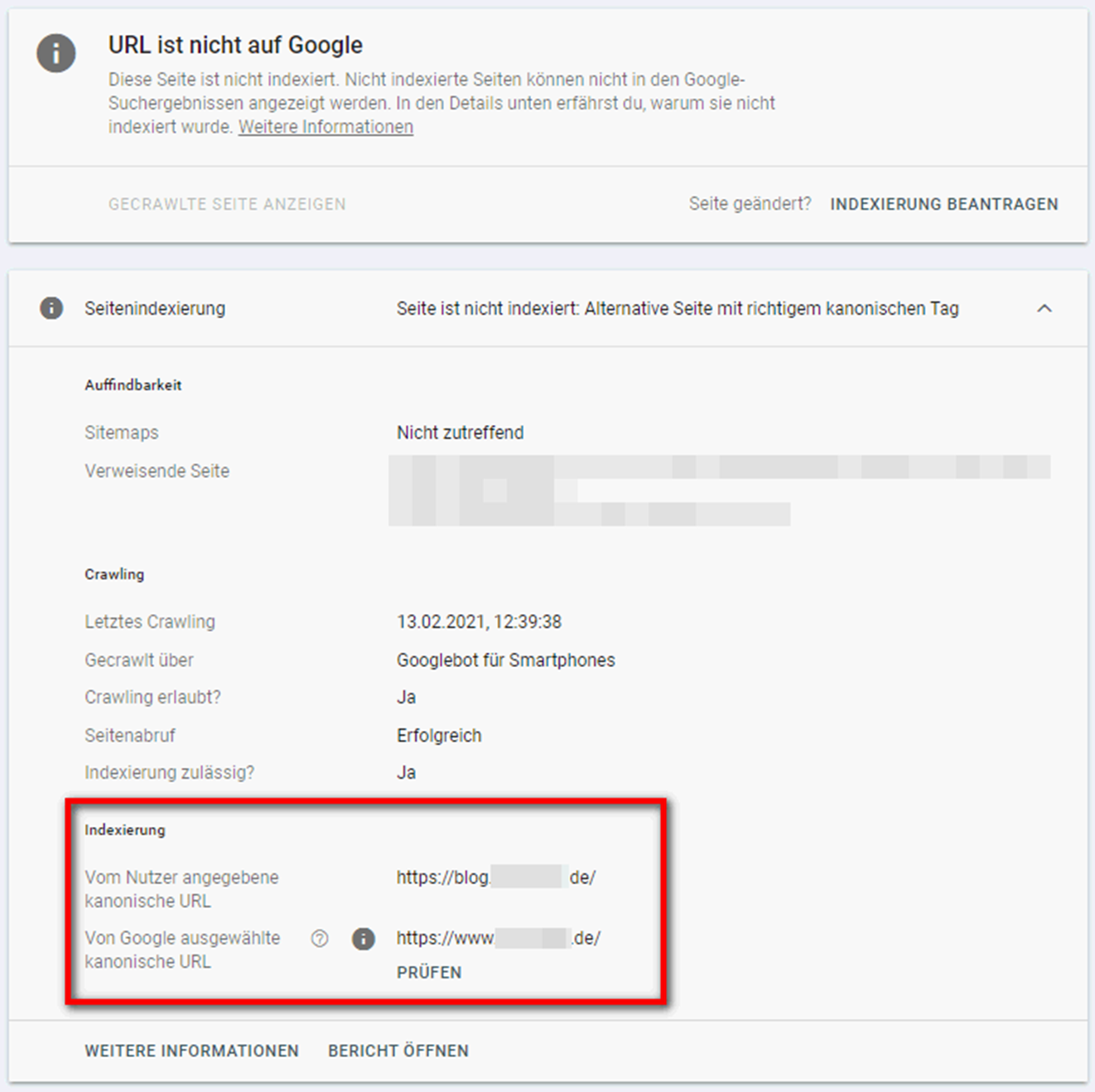
Manchmal kommt es auch vor, dass Google eine andere Seite als der Nutzer für kanonisch hält. Hier sollte überprüft werden, ob Google tatsächlich die richtige Seite ausgewählt hat:
Im nachfolgenden Video erklärt Nora von Seokratie die Fehlermeldung und mögliche Lösungswege anhand weiterer, anschaulicher Beispiele:

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Genauere Informationen zum Umgang mit Duplikaten und Canonical Tags erhalten Sie außerdem im weiteren Verlauf dieses Beitrags (“Duplikat – vom Nutzer nicht als kanonisch festgelegt” und “Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt”).
Die Fehlermeldungen “Gefunden – zurzeit nicht indexiert” und “Gecrawlt – zurzeit nicht indexiert” sind sich recht ähnlich und eng mit der Website-Qualität einer Seite verknüpft. Es gibt jedoch einige Unterschiede:
Gefunden – zurzeit nicht indexiert
Hier hat Google die URLs über die Sitemap oder interne Verlinkungen gefunden. Im Bericht zur Indexabdeckung heißt es außerdem, dass die Website beim Crawling-Versuch überlastet gewesen sei, sodass das Crawling erneut geplant wurde.
Gecrawlt – zurzeit nicht indexiert
Die aufgelisteten URLs wurden von Google zwar gecrawlt, jedoch nicht indexiert. Sie könnten in Zukunft dennoch indexiert werden.
Die Google Search Console gibt hier leider keine Auskunft über den Grund der Nicht-Indexierung. Erfahrungsgemäß liegt die Ursache aber in einer geringen Website-Qualität. Diese kann sich wie folgt äußern:
Unabhängig davon, welche Ursache der Nicht-Indexierung zugrunde liegt, kann es in einigen Fällen bereits helfen, die Indexierung in der GSC zu beantragen. Hier eine kurze Anleitung:
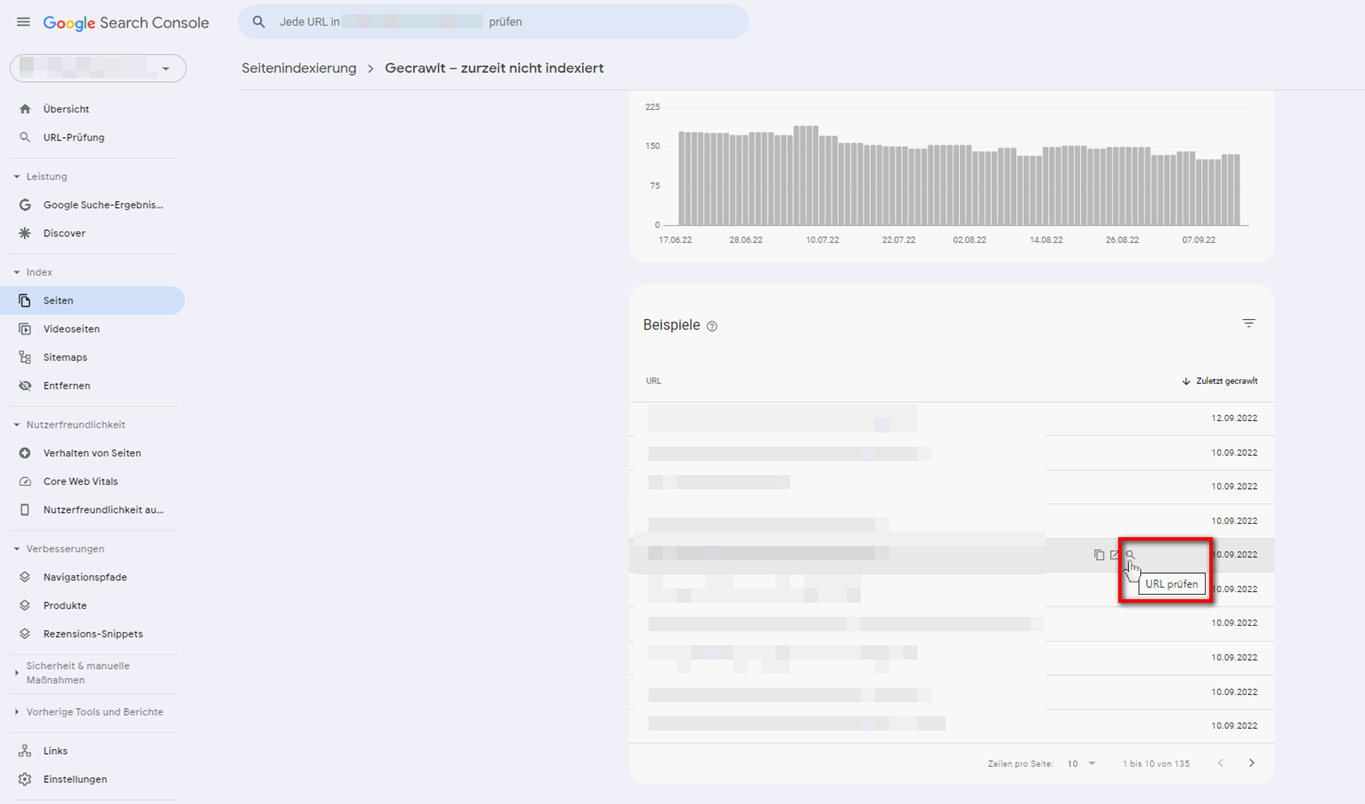
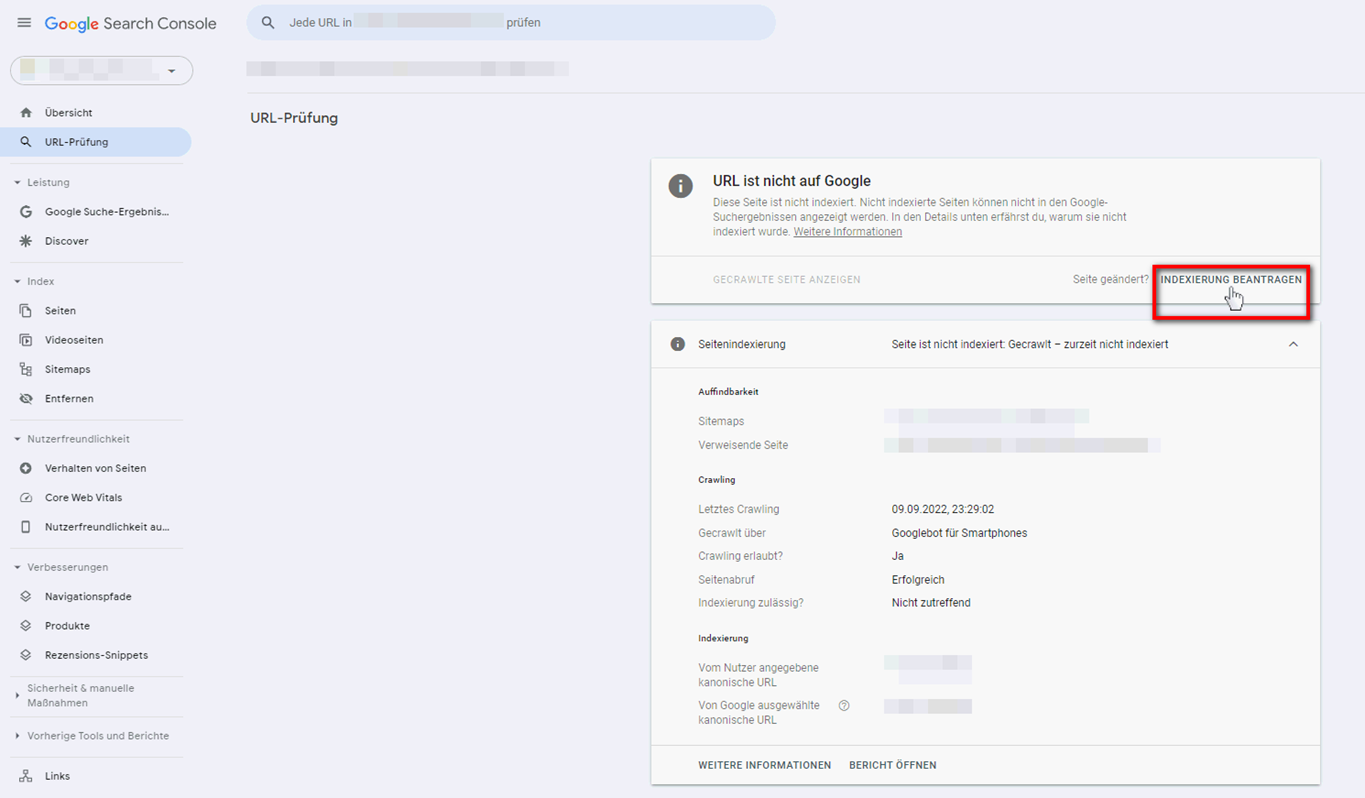
Wird eine Seite, auch nachdem Sie die Indexierung beantragt haben, nicht in den Index genommen, können folgende Lösungswege helfen:
Interne Verlinkung verbessern
Die internen Verlinkungen einer Website geben Google einen wichtigen Anhaltspunkt dafür, welche URLs die Wichtigsten sind. Umso mehr interne Verweise eine Seite erhält, desto relevanter wird sie von Google betrachtet. Darüber hinaus spielt aber auch die Position der Verlinkung eine wichtige Rolle. Verlinken Sie die Seite, die Sie indexieren möchten, an möglichst prominenter Stelle – zum Beispiel in der Navigation, auf der Startseite oder im Footer.
Hinweis!
Nicht nur interne Verlinkungen geben Google Hinweise zur Relevanz einer Seite. Auch Verweise externer Seiten, sogenannte Backlinks, signalisieren Relevanz.
Content ausbauen / verbessern
Eine weitere Möglichkeit, Google die Relevanz einer Seite zu signalisieren, ist der Content. Dieser sollte daher unbedingt ausgebaut werden. Orientieren Sie sich hinsichtlich Inhalt und Länge am besten immer an den Top-10 Seiten, die zum jeweiligen Keyword in den Google Suchergebnissen ranken.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Achten Sie neben den eigentlichen Inhalten unbedingt auch auf eine übersichtliche Darstellung sowie gute Lesbarkeit. Auch die Performance Ihrer Seite sollte stimmen. Dies umfasst schnelle Ladezeiten, eine einwandfreie Darstellung (Mobil und Desktop) sowie das Bestehen der Core Web Vitals.
Betroffene URLs werden laut Google durch eine Autorisierungsanforderung für den Googlebot blockiert. Das heißt, die URL gibt einen 401-Fehlercode zurück und der Googlebot ist nicht berechtigt, auf die URL zuzugreifen. Die Ursache liegt entweder in Zugriffsbeschränkungen aufgrund der IP-Adresse oder darin, dass ein Nutzername und Passwort benötigt werden. Prüfen Sie die betroffenen URLs und gehen Sie wie folgt vor:
Zum Zugriffsverbot mit Statuscode 403 heißt es von Google: “Der User-Agent hat Anmeldedaten gesendet, hat aber keinen Zugriff. Der Googlebot sendet allerdings niemals Anmeldedaten. Die Fehlermeldung des Servers ist deshalb falsch.” In der Regel wurden betroffene URLs bewusst durch eine Zugriffssperre gesperrt, beispielsweise der Login-Bereich.
Häufig ist das Zugriffsverbot der URLs gewünscht. Ist dies der Fall, sollte die Seite darüber hinaus durch einen “noindex”-Tag oder die robots.txt-Datei blockiert werden. Soll die Seite dagegen vom Googlebot gecrawlt werden, sollten Sie nicht angemeldete Nutzer zulassen oder den Googlebot auf die Zulassungsliste setzen.
Unter dieser Fehlermeldung werden URLs gelistet, bei deren Abruf eine 404-Fehlermeldung zurückgegeben wurde. In vielen Fällen handelt es sich dabei um alte, inaktive Seiten. Google crawlt diese manchmal, vor allem wenn sie intern oder extern verlinkt sind oder mit der Sitemap eingereicht werden (siehe Screenshots).
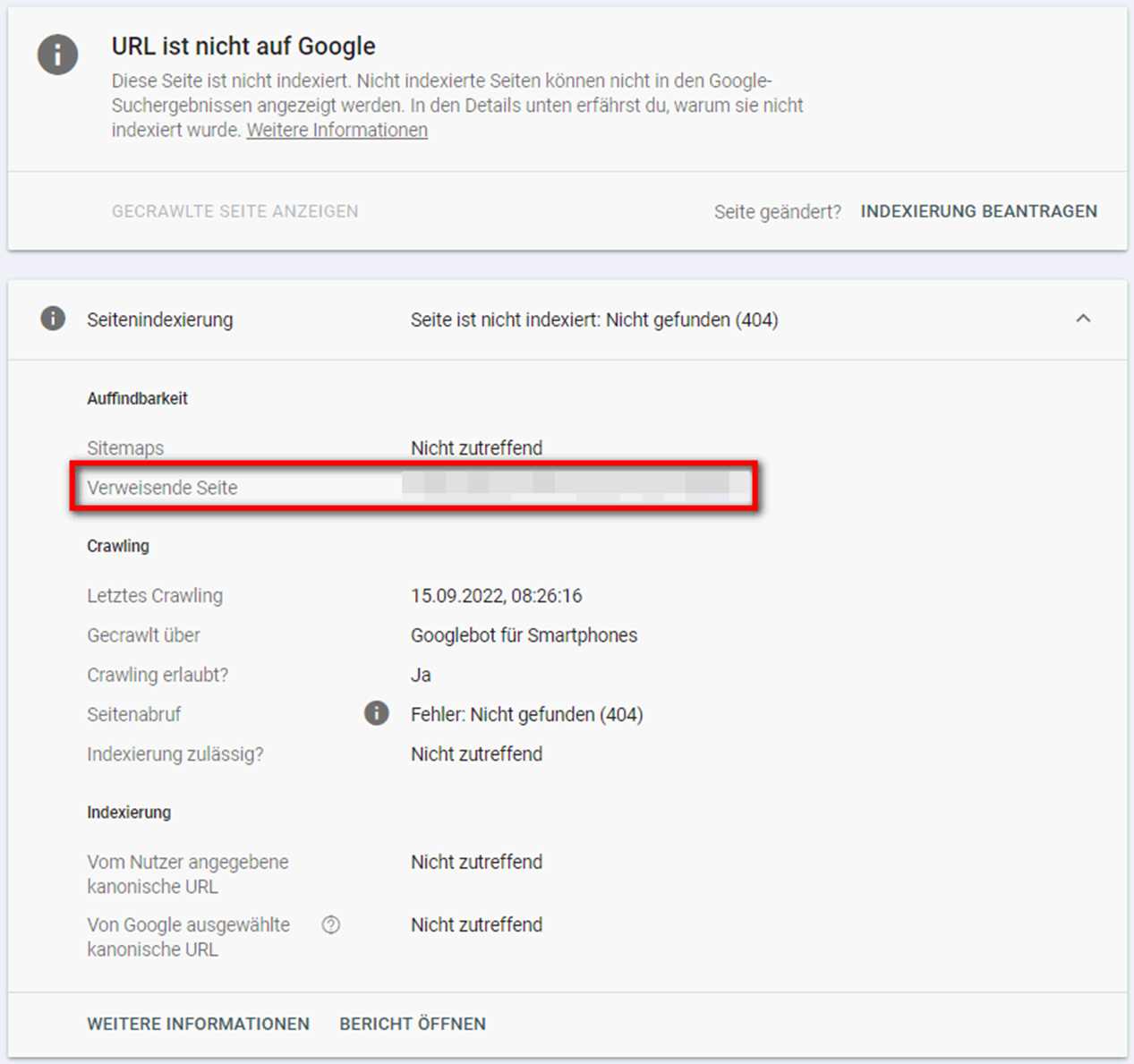
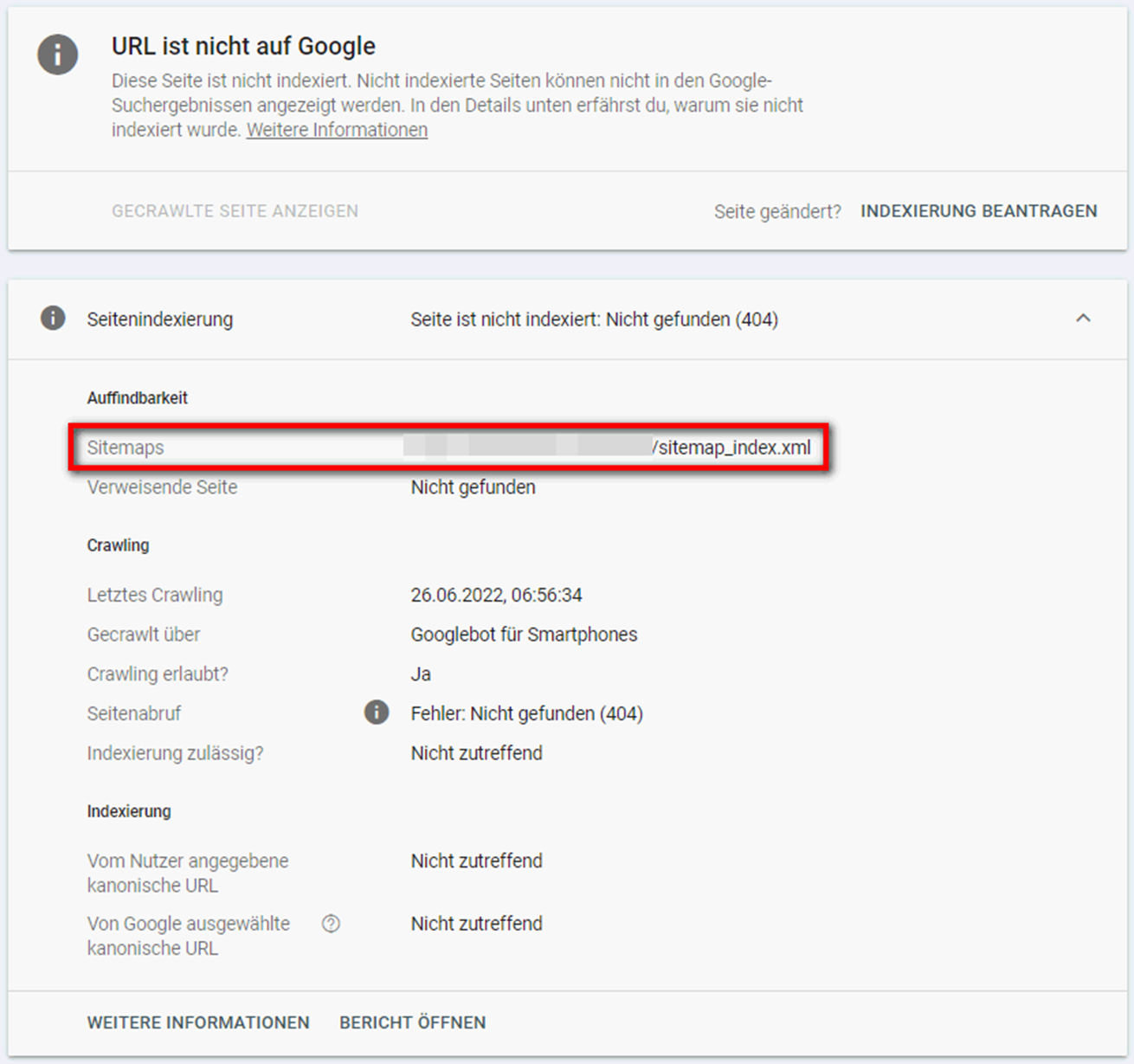
Grundsätzlich gibt es folgende Lösungen, um die Fehlermeldung “Gesendete URL nicht gefunden (404)” zu beheben:
Fehlerhafte interne Verlinkungen gilt es zu vermeiden. Ist eine Seite mit Statuscode 404 intern verlinkt, sollte die Verlinkung also entweder entfernt oder die Seite auf eine andere, möglichst passende URL (notfalls Startseite) weitergeleitet werden. Letzteres gilt vor allem dann, wenn die 404-URL weiterhin Traffic generiert oder Backlinks erhält. Befindet sich eine 404-Seite in der Sitemap, sollte sie entsprechend entfernt werden.
Bei gewöhnlichen 404 Fehlermeldungen senden Server beim Aufruf also einen 404 Fehlercode, wenn eine angeforderte Seite nicht (mehr) vorhanden oder fehlerhaft ist. In den meisten Fällen ist das Löschen von Seiten oder die Umbenennung von URLs eine Ursache. Beim Soft 404-Fehler antworten Server dagegen nicht mit einem 404-, sondern mit einem 200- oder 302-Statuscode, obwohl die Seite nicht mehr vorhanden ist und eigentlich eine 404-Fehlermeldung die richtige Antwort wäre.
Werden Ihnen in der Google Search Console Soft 404-Fehler gemeldet, prüfen Sie die betroffene URL:
Im nachfolgenden Video erklärt Markus Hövener von Bloofusion noch einmal im Detail, was die Fehlermeldung “Soft 404” bedeutet und wie Sie am besten vorgehen:
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Hinweis!
Für die Prüfung von URLs existieren unzählige Tools. Neben dem URL-Inspection Tool der Google Search Console können Sie auch andere Tools wie den Screaming Frog SEO Spider oder Bulk URL verwenden.
Hier gibt der Server eine 4xx–Fehlermeldung zurück, die zu keiner der vorangegangenen 4xx-Probleme passt. Betroffene URLs müssen individuell überprüft werden. Nutzen Sie hierfür ebenfalls die im vorherigen Abschnitt erwähnten URL-Prüftools. Wie Sie die Fehler am besten beheben, hängt von den Ergebnissen des URL-Checks ab.
Die Fehlermeldung “Duplikat – vom Nutzer nicht als kanonisch festgelegt” bezieht sich auf die im Abschnitt “Alternative Seite mit richtigem kanonischen Tag” bereits beschriebenen Duplikate, für die kein kanonischer Tag hinterlegt wurde. Google bestimmt die kanonische URL (also das Original) in diesem Fall eigenständig und stuft die betroffene/ausgeschlossene URL nicht als kanonisch ein. Prüfen Sie betroffene URL, um herauszufinden, welche Seite Google als kanonisch einstuft:
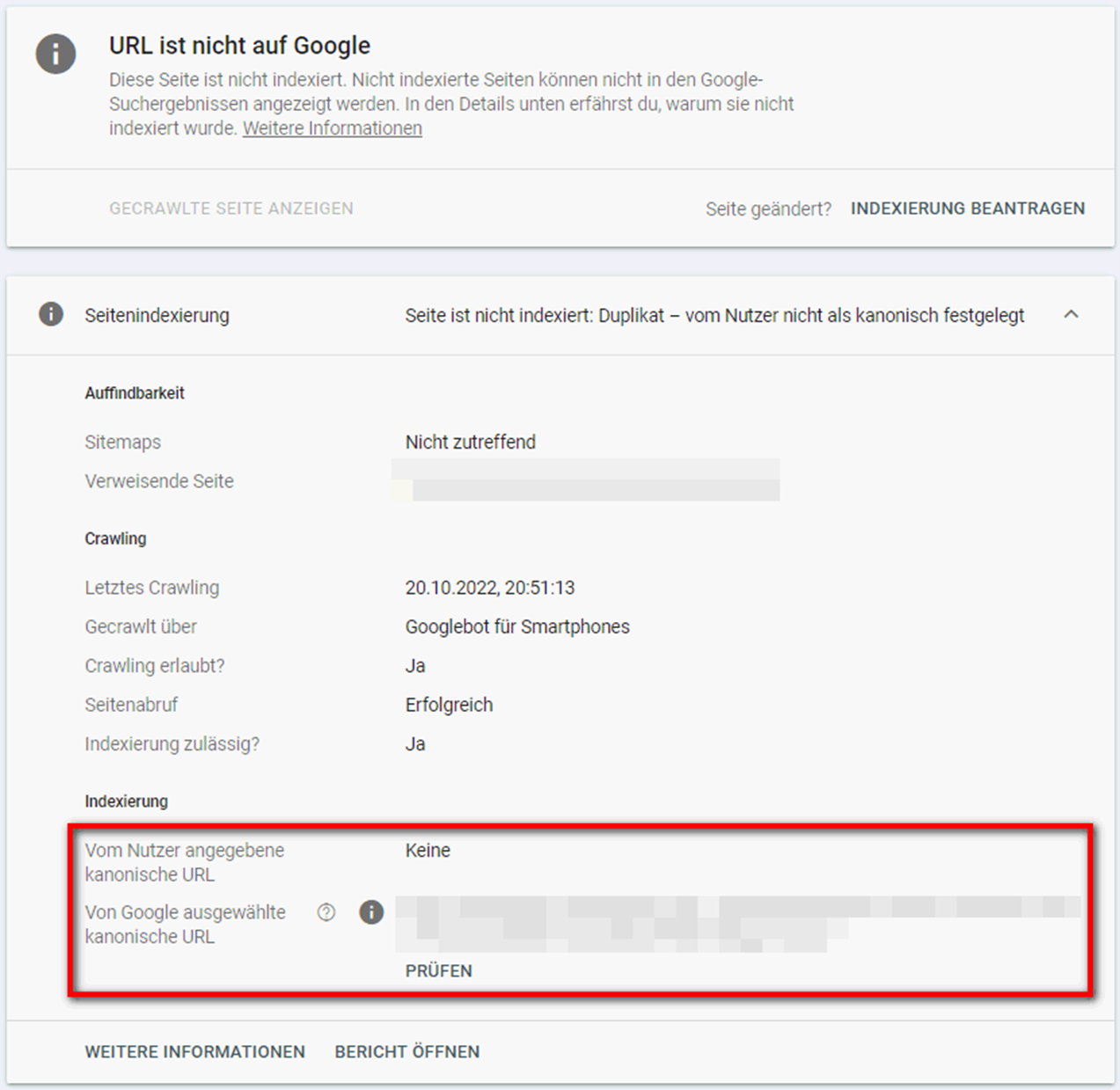
Hat Google die richtige URL als kanonisch bestimmt, brauchen Sie nichts weiter zu unternehmen. Hat Google dagegen eine falsche URL als kanonisch bestimmt, sollten Sie die richtige kanonische Seite angeben.
Hier wurde zwar eines der Duplikate als kanonisch gekennzeichnet, jedoch eignet sich aus Sicht von Google eine andere URL besser als kanonische Seite. In der Folge indexiert Google die eigenständig ausgewählte URL anstelle der von Ihnen als kanonisch bestimmten Seite. Überprüfen Sie auch hier wieder die betroffene URL, um herauszufinden, welche Seite Google als Original bestimmt hat.
Sind Sie der Meinung, dass es sich bei der von Google ausgewählten Seite nicht um ein Duplikat handelt oder Google die falsche Seite ausgewählt hat, sollten Sie die Inhalte der betroffenen Seiten so anpassen, dass sich diese voneinander unterscheiden. Alternativ können Sie auch die von Google als kanonisch bestimmte Seite auf “noindex” setzen und so aus dem Index entfernen. Überprüfen Sie hier in den nächsten Tagen und Wochen aber unbedingt, ob Google die von Ihnen ursprünglich als kanonisch bestimmte Seite indexiert. Beantragen Sie die Indexierung der URL auch gerne händisch, nachdem Sie das Duplikat aus dem Index entfernt haben, um diesen Prozess zu beschleunigen.
Die Google Search Console stellt für Website-Betreiber und Suchmaschinenoptimierer ein überaus wichtiges Tool zur Optimierung von Webseiten dar. Neben konkreten Daten zur Sichtbarkeit in Suchmaschinen, lassen sich auch wichtige Erkenntnisse zu Maßnahmen und deren Priorisierung ableiten. Im Abdeckungsbericht sollten Sie vor allem die ausgeschlossenen Seiten im Detail betrachten. Um Probleme im Bereich Indexierung zu beheben, befolgen Sie die Ausführungen dieses Beitrags. Beachten Sie dabei aber immer, dass nicht alle der aufgeführten Fehlermeldungen auch tatsächlich problematisch sind. Hier empfiehlt es sich, die Fehlermeldungen individuell zu betrachten und ggf. Optimierungsmaßnahmen abzuleiten und zu priorisieren.
Wir von seonicals® sind bereits seit über 15 Jahren im Bereich der Suchmaschinenoptimierung tätig und wissen daher genau, worauf es ankommt. Als kompetenter Ansprechpartner ermitteln wir in einer ausführlichen SEO-Analyse zunächst Probleme und Potenziale Ihrer Website und leiten priorisierte Handlungsempfehlungen ab. Als Full-Service-Agentur begleiten wir darüber hinaus auch gern die Umsetzung der vorgeschlagenen Maßnahmen. Senden Sie uns noch heute eine Anfrage und vereinbaren Sie ein kostenloses, unverbindliches Erstgespräch, um die Sichtbarkeit Ihrer Website nachhaltig zu steigern!
Die Google Search Console bezieht sich vor allem auf eine Website (Klicks, Impressionen, CTR, Nutzerfreundlichkeit etc.), während der Fokus bei Google Analytics eher auf dem Publikum (Absprungrate, Sitzungsdauer, Konversionen etc.) liegt. Viele User nutzen die Analysetools gemeinsam, um möglichst umfassende Informationen zu erhalten.
Bei der Google Search Console (kurz: GSC), die ehemals auch als Google Webmaster Tools bezeichnet wurde, handelt es sich um ein kostenfreies Google-Tool zur Analyse und Optimierung von Websites. Die GSC gibt zahlreiche Empfehlungen zur Optimierung einer Website. Darüber hinaus erhalten Nutzer Warnungen bei Problemen.
Crawler erfassen (“crawlen“) automatisch Webseiten. Dabei folgen sie Verlinkungen von Seite zu Seite und speichern Informationen darüber, was sie auf diesen Seiten finden. Beim Crawling kann der Google-Bot natürlich auf Inkonsistenzen (z. B. durch Verlinkung nicht existenter Seiten, Serverfehler, mangelnde Zugriffsrechte, etc.) stoßen. Die Summe solcher Inkonsistenzen wird als Crawling Fehler bezeichnet.
Zu dieser Fehlermeldung heißt es von Google: “Ihr Server hat bei Anforderung der Seite einen 5xx-Fehler zurückgegeben”. Das bedeutet, dass der Googlebot entweder nicht auf die Seite zugreifen konnte, die Anfrage abgelaufen ist oder die Website ausgelastet war und die Anfrage deshalb abgebrochen wurde.
Johannes Böttner
Johannes ist nicht nur SEO-Experte, sondern schreibt auch leidenschaftlich gern Texte über alle Online-Marketing-Themen.

Teile diesen Artikel




Sie machen den ersten Schritt. Wir übernehmen den Rest.
Wir bieten Ihnen eine kostenfreie Beratung, vor Ort oder online, in der wir Ihre Online-Marketing-Strategie analysieren und passende Maßnahmen für Ihren Erfolg identifizieren.
